
Quando si crea un sito web, uno degli obiettivi principali è far sì che venga trovato dai motori di ricerca come Google, Bing o DuckDuckGo. Per riuscirci, è fondamentale comprendere come questi strumenti esplorano e interpretano le pagine del tuo sito. Uno degli elementi chiave di questo processo è il file robots.txt.
Si tratta di un semplice file di testo che fornisce istruzioni ai motori di ricerca su quali parti del sito possono essere esplorate e quali invece dovrebbero essere ignorate. Anche se tecnicamente è molto semplice, il suo utilizzo corretto può avere un impatto significativo sulla visibilità del sito nei risultati di ricerca.
Cos’è il file robots.txt
Il file robots.txt fa parte del cosiddetto Robots Exclusion Protocol, uno standard di fatto utilizzato dai motori di ricerca per capire come comportarsi quando visitano un sito web. Questo file viene posizionato nella directory principale del sito ed è uno dei primi file che i crawler cercano quando arrivano su un dominio.
Il crawler (chiamato anche spider o robot) è un programma software che naviga in Internet in modo automatico e metodico per analizzare i contenuti dei siti web.
Attraverso il robots.txt, chi gestisce il sito può:
- Consentire o bloccare l’accesso a specifiche pagine o cartelle
- Dare istruzioni diverse a motori di ricerca differenti
- Ridurre il carico sul server evitando scansioni inutili
- Controllo dei Bot di Intelligenza Artificiale in modo da usare il robots.txt per negare l’accesso ai bot che “pescano” dati per addestrare modelli di AI, proteggendo così la proprietà intellettuale dei propri contenuti.
È importante chiarire che il robots.txt non protegge contenuti riservati, ma indica solo ai crawler cosa dovrebbero o non dovrebbero esplorare (indicazioni generalmente rispettate dai crawler affidabili come quello di Google).
A cosa serve
Il principale scopo del file robots.txt è gestire la scansione del sito. In pratica, aiuta i motori di ricerca a concentrarsi sulle pagine più importanti, evitando contenuti duplicati, sezioni tecniche o pagine che non hanno valore SEO.
Alcuni esempi di utilizzo comune includono:
- Bloccare cartelle di amministrazione come /wp-admin/
- Evitare l’indicizzazione di pagine di test
- Impedire la scansione di risultati di ricerca interni
- Ottimizzare il crawl budget, il numero limitato di pagine che un motore di ricerca decide di scansionare su un sito web in un determinato periodo di tempo.
Per chi è alle prime armi, il robots.txt rappresenta uno strumento semplice ma potente per iniziare a controllare il comportamento dei motori di ricerca.
Dove si trova e come creare il file robots.txt
Il file deve essere posizionato nella root del sito, ovvero la cartella principale del dominio. Se non esiste, è possibile crearlo facilmente utilizzando un qualsiasi editor di testo.
Il file robots.txt deve essere leggibile pubblicamente affinché i crawler dei motori di ricerca (come Googlebot o Bingbot) possano accedervi e seguire le istruzioni contenute.
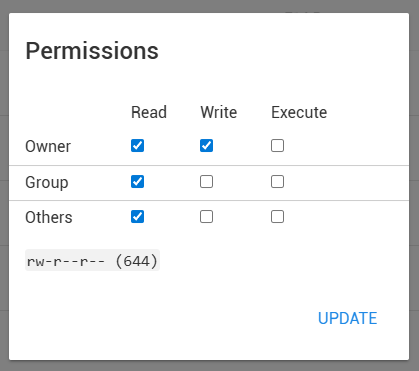
In termini tecnici, sui server basati su Linux/Unix, il permesso standard consigliato è 644.
Il codice numerico 644 definisce chi può fare cosa con il file:
- Proprietario (6): Può leggere e scrivere (modificare) il file.
- Gruppo (4): Può solo leggere il file.
- Altri/Pubblico (4): Può solo leggere il file.
Il file deve:
- Chiamarsi esattamente robots.txt
- Essere tutto in minuscolo
- Essere accessibile pubblicamente
Su WordPress, spesso il file viene generato automaticamente, ma può essere personalizzato manualmente o tramite plugin SEO.
Struttura base del file robots.txt
La struttura del file è molto semplice. Le regole principali sono:
- User-agent: indica a quale crawler si applica la regola
- Disallow: indica cosa non deve essere scansionato
- Allow: indica cosa è consentito
Esempio base:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Questo esempio dice a tutti i motori di ricerca di non scansionare la cartella wp-admin, tranne un file specifico necessario al corretto svolgimento della scansione di contenuti caricati dinamicamente..
Errori comuni da evitare
Molti principianti commettono errori che possono compromettere la visibilità del sito.
Tra gli errori che possono capitare, i più frequenti sono:
- Bloccare involontariamente l’intero sito
- Confondere robots.txt con noindex
- Usare regole troppo generiche
- Dimenticare di testare il file
Un singolo errore nel robots.txt può impedire ai motori di ricerca di scansionare pagine fondamentali.
Come testare il file robots.txt
Google Search Console offre uno strumento dedicato per testare il file robots.txt (Impostazioni > robots.txt > Apri rapporto > Icona menu kebab > Richiedi una nuova scansione). Questo permette di verificare se una pagina è bloccata o consentita e di individuare eventuali errori di sintassi.
Testare il file è un passaggio essenziale, soprattutto dopo ogni modifica.
Gestire correttamente il file robots.txt
Il sito web evolve nel tempo, e così deve fare anche il file robots.txt. Ogni nuova sezione, plugin o funzionalità può richiedere un aggiornamento delle regole.
È buona pratica:
- Controllare il file periodicamente
- Aggiornarlo dopo modifiche strutturali
- Tenerlo il più semplice possibile
Gestire il file robots.txt significa imparare a dialogare con i motori di ricerca in modo chiaro e strategico. Comprendere le basi di questo file consente di evitare errori gravi e di migliorare gradualmente la SEO del proprio sito.